METS Server #966
METS Server #966
Conversation
There was a problem hiding this comment.
Hi, here is my review. I read through all the code and briefly tested the new feature.
This review-comment has 3 parts: questions, uds, tests. Feedback to fastapi are included in my code-comments
Questions:
-
Maybe we/you could point out the idea of the Mets-Server again (then it is better for me to recap): IIUC the idea is that all interactions with a workspace are done by the Mets-Server. So there is just one process (the server) accessing the Metsfile. What I am wondering is: when a user initiates multiple calls to the server how is it ensured that the Metsfile is accessed in a "synchronized way". Can't it be for example that the Met-Server itself receives 2 requests to add a file to the Metsfile and this calls "happen at the same time" and thus the writes collide somehow? Or is this related somehow to the Metsfile caching? Or because python only has one thread?
Processors do still need to specify the workspace directory because they read files from disk
I don't understand what you mean by this. Does it mean in addition to host/port the path to the workspace has to be specified? If so why, as far as I understand the Mets-Servers is the only one who needs to know where the Metsfile is stored.
whether downloading from the server should be A Thing
sry, I don't understand that either, can you try to clarify? Do you mean we should thing about if we should offer the functionality to download the Metsfile and the filegroups and everything?
Unix sockets
I don't have much experience with unix sockets. What is the benefit in using sockets compared to using tcp? I am wondering if it's worth the added "complexity" because both (uds and tcp) offer nearly the same thing (iiuc). What I would do is go with tcp and drop the sockets at least for the beginning (although it seems to be nicely usable with uvicorn/fastapi).
Tests
I didn't think very much about the tests yet. I am wondering if it is time for that yet, I know about TDD but I think I am not experienced/used to do that.
But in the webapi-implementation we already have some tests regarding fastapi. There we also use pytest-docker because we need mongodb (and later probably rabbit-mq) as well. I am not sure weather we need this also for the metsserver yet. Currently I don't think so.
Testing api endpoints with fastapi is in my opinion simple (using docker is a bit more complicated from my point of view). First a fixture (not mandatory but I think a fixture is the best way) for the fastapi-Instance/TestClient is needed: https://github.com/OCR-D/ocrd-webapi-implementation/blob/main/tests/conftest.py#L33-L36 (let's pretend as if in the example the function has no parameter) and then it can be used to execute http methods: https://github.com/OCR-D/ocrd-webapi-implementation/blob/main/tests/conftest.py#L176-L177. The rest (starting the server etc) is done by fastapi in the background.
|
Hi Jonas. I will try to provide some insight on the questions you asked as far as I understand, Konstantin can then modify/extend the answers. In the end, hopefully, all of us will be on the same page.
That's correct.
Good question. Still not completely clear to me as well. On a low level, how does the Session from
We have two different options for the mets server:
I guess, yes - I have the same understanding. Whether the mets server should download missing files. Although I think this does not include downloading the mets file, just whatever is referenced inside the mets file.
In short - the Unix socket is used for interprocess communication (IPC) and is an alternative to native IPC (e.g., pipes and fifos) . In cases where the mets server and the ocrd processor/s are running on the same host, the communication happens in a more efficient way (check here and here). The data transferred over the socket can also be further compressed - e.g., using a message scheme instead of relying on the slower JSON schema (EDIT: message compression is possible over TCP as well, but usually not preferred if users interact with the server directly and they need meaningful responses, JSON is ideal in that case). The mets server will be accessed by ocrd processors and not by users directly. The user is only interested in the latest mets file state once the processing is finished. Another HPC-specific advantage is that it completely removes any possibility of potential port clashes with other running services. When I asked a more experienced person about starting a mets server inside the HPC, I've been told to always use ports above 10000 to reduce the possibility of potential port clashes with internal services. However, this is still not safe enough in the long run since it can still potentially clash with another user service. The more mets server instances inside the HPC, the more probability of a clash.
I would not prefer to drop the sockets. However, I think we should separate the |
Co-authored-by: Mehmed Mustafa <mehmed.n.mustafa@gmail.com>
Co-authored-by: joschrew <91774427+joschrew@users.noreply.github.com>
The METS server is single-threaded, so any concurrent requests will work on the same in-memory
The way the METS server is currently implemented still requires processors to be run with a local copy of the workspace, only file adding and searching (and a few related methods) are implemented, access to the actual files happens via filesystem. I was wondering whether we should decouple this further, so that a processor can request a file and download it via the METS server, store it in a local scratch directory (or just keep in memory if feasible), do the processing and upload the file again. That way there would be no need to have a processor-local full workspace at all. The other interpretation does also make sense though, i.e. downloading misssing files to the server-local workspace, like we do with the
I would also prefer to keep both options for the reasons @MehmedGIT explained so eruditely above. If you have suggestions on how to better describe the features, I'll be happy to integrate them. |
Since
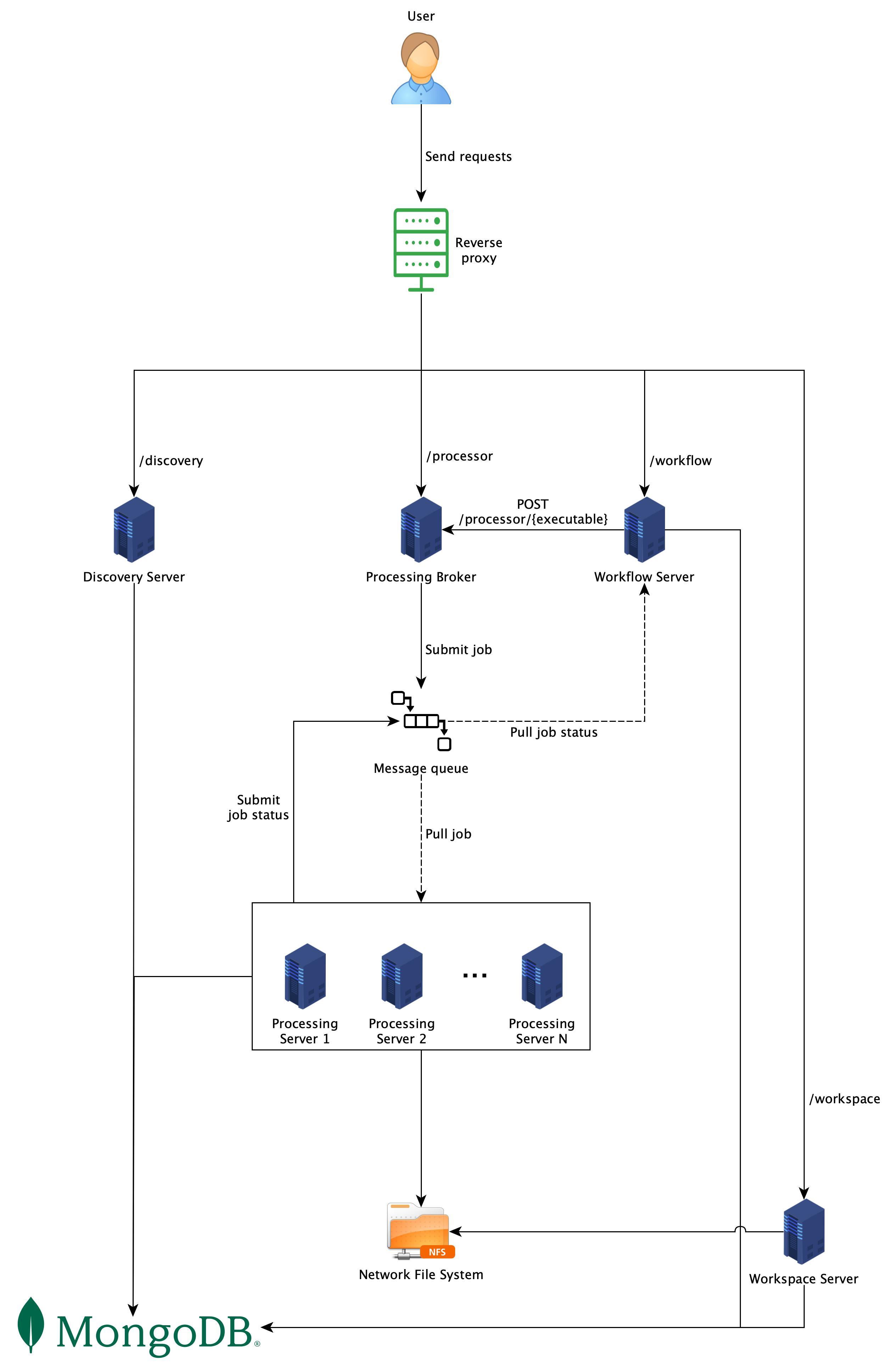
This sounds reasonable considering that the processors should know nothing regarding the workspace structure but just process images. However, we should think how to optimize that to avoid unnecessary transfers of images. E.g., uploading images from Local/Network FS to the METS server, then sending them to the processors via the METS server. Maybe we should first try to identify a spot where the METS Server fits the best in this architecture. I think the METS Server fits the best between the |
{kind=link}
There was a problem hiding this comment.
Overall looks good. We already discussed some things in person but for the record here is a bug that is still there.
- Starting the METS Server:
ocrd workspace -U http://localhost:8123 -d /home/mm/Desktop/example_ws2/data server start - Then trying to run some processor:
ocrd-cis-ocropy-binarize -U http://localhost:8123 -I DEFAULT -O OCR_BIN
Output:
17:29:31.758 CRITICAL root - initLogging was called multiple times. Source of latest call:
17:29:31.758 CRITICAL root - File "/home/mm/Desktop/ocrd_core/ocrd-core/ocrd/ocrd/decorators/__init__.py", line 60, in ocrd_cli_wrap_processor
17:29:31.759 CRITICAL root - initLogging()
Traceback (most recent call last):
File "/home/mm/venv37-ocrd/bin/ocrd-cis-ocropy-binarize", line 8, in <module>
sys.exit(ocrd_cis_ocropy_binarize())
File "/home/mm/venv37-ocrd/lib/python3.7/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/home/mm/venv37-ocrd/lib/python3.7/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/home/mm/venv37-ocrd/lib/python3.7/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/mm/venv37-ocrd/lib/python3.7/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/home/mm/venv37-ocrd/lib/python3.7/site-packages/ocrd_cis/ocropy/cli.py", line 18, in ocrd_cis_ocropy_binarize
return ocrd_cli_wrap_processor(OcropyBinarize, *args, **kwargs)
File "/home/mm/Desktop/ocrd_core/ocrd-core/ocrd/ocrd/decorators/__init__.py", line 80, in ocrd_cli_wrap_processor
workspace = resolver.workspace_from_url(mets, working_dir)
File "/home/mm/Desktop/ocrd_core/ocrd-core/ocrd/ocrd/resolver.py", line 175, in workspace_from_url
self.download_to_directory(dst_dir, mets_url, basename=mets_basename, if_exists='overwrite' if clobber_mets else 'skip')
File "/home/mm/Desktop/ocrd_core/ocrd-core/ocrd/ocrd/resolver.py", line 82, in download_to_directory
raise FileNotFoundError("File path passed as 'url' to download_to_directory does not exist: %s" % url)
FileNotFoundError: File path passed as 'url' to download_to_directory does not exist: /home/mm/Desktop/ocrd_core/mets.xml
Seems it still tries to find the mets.xml file in the default path.
I have tried to provide the correct mets path with --mets, however, then the produced output files are not reflected by the METS Server at all.
|
EDIT:
You also need to specify the path to the workspace to the processor, like so:
Because writing out files other than But there were indeed a few problems in the code, that I have fixed now (mostly that I have now tested it with https://content.staatsbibliothek-berlin.de/dc/PPN680203753.mets.xml:
It takes a moment for the processes to start, but then they go brrrr. |
|
Tests now fail due to psf/requests#6226 but have to investigate further tomorrow. |
PR is for early feedback, this is a proof-of-concept, not yet ready for wider use because it is not tested systematically yet.(it is tested and largely consolidated now 🤞)METS server can be started with:
Note: If you want to use the TCP interface, you must prefix the
--mets-server-urlwithhttp://, otherwise it will be interpreted as a UDS.Then you can do things like
OcrdMets.find_filesvia http:http get localhost:8123 file_grp=OCR-D-IMG "mimetype=//image/.*"The same can be achieved through
ocrd workspace:ocrd workspace -U /tmp/ws.sock find -G OCR-D-IMG -m "//image/.*"And processors also accept
-U/--mets-server-url:Processors do still need to specify the workspace directory because they read files from disk.
Should we go further and provide a way to download files from the METS server?We should not.The implementation (in
ocrd.mets_server) works like this:OcrdMetsServeris the server component. It is provided with a workspace and calling itsstartupmethod creates a fastapi app that is run with uvicorn.ClientSideOcrdMetsis a replacement forOcrdMetsthat delegates to theOcrdMetsServerinstead of the lxml DOM.ClientSideOcrdFileis the equivalent replacement forOcrdFileClientSideOcrdAgentis the equivalent replacement forOcrdAgentOcrdWorkspace,ocrd_decoratorsetc. acceptmets_server_urlin addition tomets_url,mets_basenameetc. If--mets-server-urlis specified, theOcrdWorkspace.metsis instantiated as aClientSideOcrdMetsinstead ofOcrdMets. The idea behind this, is that the change in behavior should be largely transparent, there are very few changes toOcrdWorkspaceitself, only how the METS is accessed is different, but processor developers and users ofocrd workspaceshould not need to change anything to get support for METS server.As I said, this is a proof-of-concept at this stage, there some hacky solutions in it and I haven't yet started to unit/integration test this properly.There is now a basic test.I would appreciate feedback on
the fastapi implementationthis is good enough to move forward I thinkwhether downloading from the server should be A ThingIt should notwhether we need both TCP and UNIX socketYes, adds little complexity but offers flexibilityhow best to test thisTesting with a pytest fixture where the server is run via socket in a separate process, parallel additions tested with process pools