High number of thread performance #762
Comments
|
Could this be a cache problem? Even my Ryzen 7 3800x has split L3 cache, 16MB per 4 cores, but I suspect such effects will be greater if data moves between Ryzen 9 "chiplets". The Intel parts you compared have unified cache. But don't just guess -- you should probably get familiar with a profiler like Is there anything specific to rayon that you're asking about here? |
|
hi, you can try to use the you need to create a pool from rayon_logs instead of rayon and then call logging_install to get a log. if you need some help with the crate don't hesitate to ask. |
|
Thanks for you response I will try to use perf tools. @cuviper I don't really have a specific question, just the fact that the sort is faster with 16 threads than with 32 is a bit strange. And maybe it could be a known problem. The big differences between my sort and the Regions Sort from the MIT is the language (of course), one is in C++ the other is in Rust, and the threadpool, one uses CILK, and the other uses Rayon. I have another problem but it is really the algorithmic part. Not related to thread or threadpool. |
|
I ran For the first image:
The Regions Sort uses block_size = 200_000. On the left, my sort runs in 3.8s in For the second image, it is the same but with 16 threads. Running times are a bit better with 16 threads. On the left, my sort runs in 3.1s in What I can see is the
|


|
I don't know if this could still be a problem ? |
|
cc @stjepang for the crossbeam concerns. We use that for the job queues, so if this is showing up high in your profile, it may just be that you're pushing a high number of too-small jobs. You might also want to try with #746, to see if perhaps the new scheduler doesn't contend as much.
That has to do with the |
|
Thanks for your response. I tried #746 and the first version too.
Indeed, I made changes and it improves well when there are small chunks left. I am digging this right now, I had this problem indeed. But my sort is still faster with 16 threads than with 32. |
|
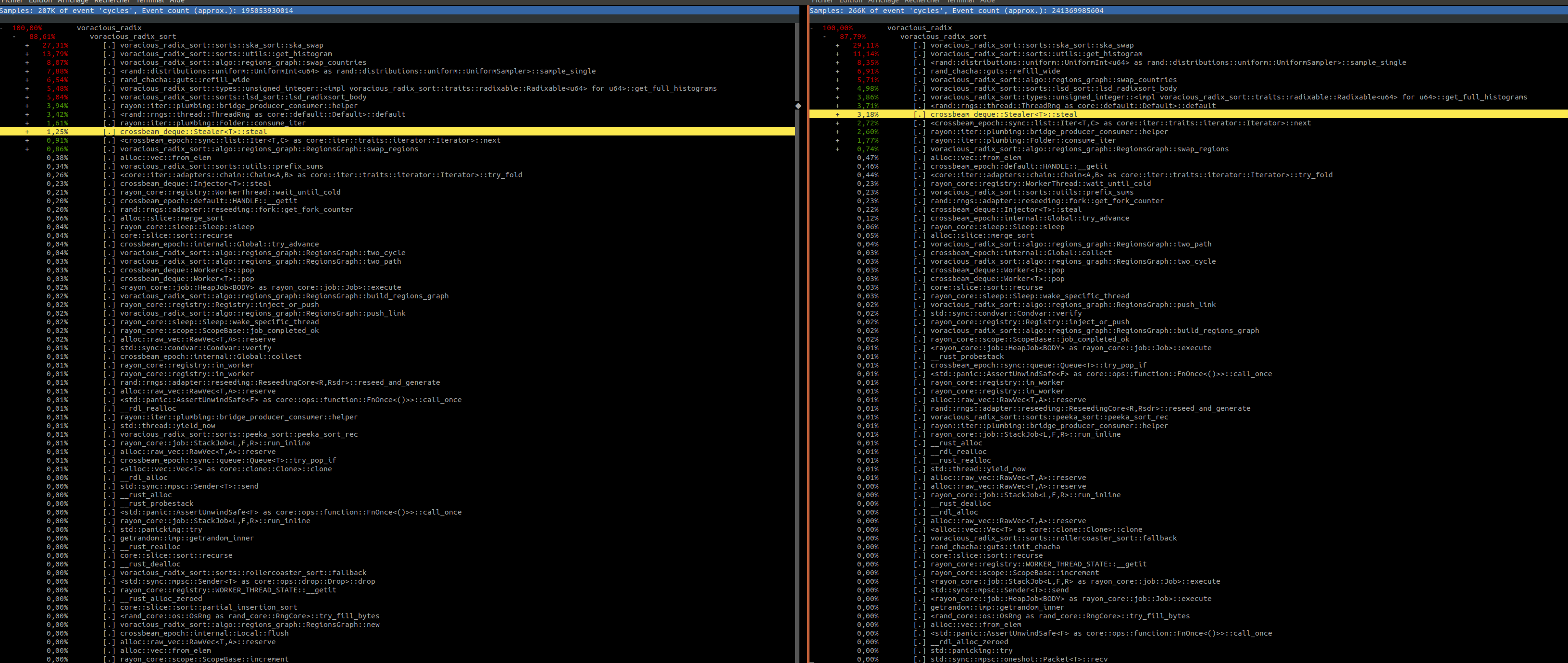
It is a while but I finally do perf on my last version of my "peeka sort" (improvement of the MIT regions sort, multithread radix sort) So the problem was (and still is) that with 32 threads, my multithread radix sort is slower than with 16 threads: With 16 threads: With 32 threads: So we can see that the big change is in the "ska_swap" which is one of the function in the sort who swap two elements in the array. |


|
I have re run a perf On the left it is with 16 threads, on the right it is 32 threads I don't see a big difference 🤔
|
Hello there.
First, thanks for you big work.
I am using your lib in my voracious_radix_sort lib and it is very helpful.
Voracious sort is a radix sort, the single thread version is already released on crates.io (and will be improve) and I am working on the multithreaded version.
For the multithreaded version, I have recoded in Rust the MIT Regions sort:
https://people.csail.mit.edu/jshun/RegionsSort.pdf
https://github.com/omarobeya/parallel-inplace-radixsort
I also keep an eye on the Raduls sort:
https://github.com/refresh-bio/RADULS
These two sorts (Regions sort and Raduls) are currently the state of the art of the multithreaded radix sorts. (one is out of place, one is inplace, both are unstable)
For my sort (an improvement of the Regions sort), as I just said, I recoded the Regions sort, and I improved it. I am strongly confident that there is a lot of improvement on the algoritmic part. So it should be faster...
I am working with the last AMD Ryzen 9 3950x with 32GB DDR4 RAM and MB X570. (I invested a lot of personal money to have a HEDP). As you may know this CPU has 16/32 cores/threads.
But, there is a but, I have problems on the scaling part.
Above 600_000_000 elements, my sort is slower than the Regions sort.
And my sort is slower with 32 threads than when I use only 16 threads.
The Regions sort is faster with 32 threads than with 16 threads.
The first though will be: yeah probably it is your code that is slower with more threads.
Indeed.
But I also have an Intel i5-8365U (4/8 cores/threads) and my Voracious sort is faster with 8 threads than it is with 4 on this CPU.
I also have an i5-4600K (4/4 cores/threads) and my Voracious sort is faster when I set 12 threads instead of the 4 threads I should use.
I spent a lot of time to try to understand why my sort behave that way, and maybe the scheduler I am using might have a flaw or something like that. That's why I am posting here to have your feed back, maybe it is an already known problem for you or maybe it just my code who is at fault. I don't know. But I can just ask and see what will be the result.
(my code is on my github, in the branch
dev)Here is a screenshot of few results.
Globally I am faster with 32bits number, but for 64bits number my sort don't scale well starting at 600_000_000 elements in the array.
As you can see, I set only 16 threads on my sort, because it is faster than when I use 32 threads.

But for the MIT Regions sort, it is faster with 32 threads, so I keep 32 threads for the Regions sort. Voracious sort is faster than the MIT Regions sort with the same number of threads, but to be fair, I set the number of thread with which the sort is the fastest on my computer.
I read another issue on your github with about the same problem, and your answer was that if the core is fully used of course, SMT or HT won't be of any help, but in the case of the radix sort, there is not a lot of work to perform, computing the index and then mostly moving items.
Thanks for your interest.
The text was updated successfully, but these errors were encountered: