本文主要论述 JavaScript Coverage 原理与实践。
覆盖率测试用于统计代码的执行情况。
在开始之前,首先介绍需要了解一些概念。
对于一段代码,从颗粒度上来看,可以划分表达式(Statement), 分支(Branch), 函数(Function), 行(Line).
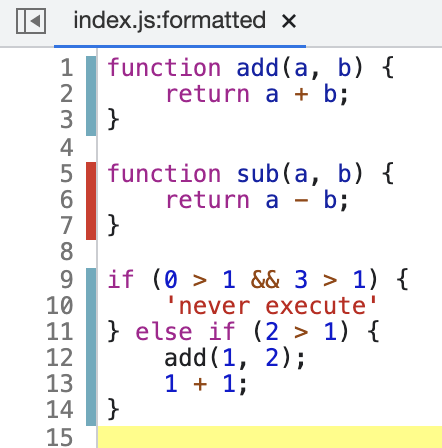
例如下列 index.js 代码:
1 | function add(a,b) {
2 | return a + b;
3 | }
4 |
5 | function sub(a,b) {
6 | return a - b;
7 | }
8 |
9 | if (0 > 1 && 3 > 1) {
10 | 'never execute'
11 | } else if (2 > 1) {
12 | add(1,2); 1+1;
13 | }
14 |当使用 nyc 对以上代码进行覆盖率分析时,可以预判到:
- 由于
0 > 1不成立,随后的'nerver execute'不会被执行,所以此行(此表达式)不会被统计; - 代码内共计两个函数
add与sub, 而sub函数必然不会执行,因此函数覆盖率为 50%; - 代码内出现了两个条件分支
if ( 0 > 1 && 3 > 1) else if ( 2 > 1), 它其实会被转化为if( 0 > 1 && 3 > 1) else { if( 2>1 ) {} else {}}, 转化后共计 6 条分支,而实际执行到的为0 > 1, 第一个else内和2 > 1共计 3 条分支。
当然,可能还存在一些分歧:
- 项目中的空行(例如第 4, 8, 14 行)是否应被统计?
- 注释是否应被统计?
- 表达式的行数如何界定?
这些分歧并没有统一的答案,一般情况下是对齐 istanbuljs, 但遗憾的是,c8 所使用的 v8-to-instrument 在这方面处理的并不好。
而由于处理方式的不同,二者生成的结果也存在差异,例如:
version:
- c8: 7.10.0;
- nyc: 15.1.0.


上图中,左图为 nyc, 右图为 c8.
TLDR: nyc 使用 babel 将需要统计覆盖率的文件进行了一层转化,执行转化后的代码可以输出覆盖率信息。
当执行 nyc node index.js 时,其执行流程如下:
- 依据参数生成配置项;
- 依据配置项生成 NYC 实例;
- 将
nyc/lib/wrap.js添加到node-preload中; - 通过
foreground开启另一个端口执行node index.js; - 先执行子进程 nyc/lib/wrap.js, 此处代码逻辑内生成了一个新的 NYC 实例并执行
- 在
wrap函数内,NYC 为满足后缀为 extensions 的增加一个 hook, 该钩子函数负责在 require 相应文件时执行相应的转换操作;同时还会在执行结束时增加一个回调函数。 - 转换操作是借助 babel 将原始代码转化为带有函数、表达式、语句、行数颗粒度等标记的代码。这些标记代码可以统计执行信息,同时也不会影响原代码的逻辑。例如:


上图中,左侧为原始代码,右图为转化后的代码。可以看出,相比于原始代码,转化后的代码体积膨胀了很多倍。
- 随后,该 require hook 执行结束,开始执行被转换后的代码,执行过程中会统计哪些代码被执行到;
- 当被转换后的代码执行结束时,执行
wrap中添加的回调函数,该函数可以将统计信息输出到nyc_output文件夹下; - 随后,该子进程执行结束,返回到父进程内;
- 在父进程中,以
nyc_output下文件内的统计信息为基础,输出各种信息,诸如 reporter, check 等。
除此之外,NYC 内还有各种工程上的细节,例如 cache, sourceMap 等处理,但这些并不是本文关注的重点,因此也不再赘述。
在绝大部分项目中,直接使用 NYC 没有任何问题。
但是,我遇到了一个边界 case: 为防止幻影依赖, 我们的项目将产物以 bundle 的形式产出,因此导致一个问题:产物非常大(约 10Mb 量级),通过 NYC 内置的 Babel 生成中间产物,再运行中间产物来生成覆盖率方式会导致各种问题:执行速度慢、因内存不够而栈溢出等。
对此,有以下几种解决思路:
- 对项目产物进行改造,例如移除 bundle 产物内的 node modules 代码;取消使用 bundle 转而重新使用 node module; 使用 dynamic import 来减小产物体积等;
- 对 NYC 进行改造,当 NYC 为产物进行代码转换时进行预处理,剔除不需要的 transform 逻辑;
- NYC 不再对产物进行预处理,而是使用项目内原始的代码。
以上几种方式都需要额外的代码量,并且可能造成工程上的参差不齐,幸运的是,我们看到了基于 Native Coverage 实现的 c8.
Native Coverage, 指 V8 内置的覆盖率功能。介绍 c8 之前,我们先看 V8 Coverage 在浏览器内的用法,假设我们有以下代码 index.html:
<!DOCTYPE html>
<head>
<title>v8 coverage</title>
</head>
<body>
<!-- 指向上文的 JavaScript 代码 -->
<script src="./index.js"></script>
</body>
</html>用浏览器 devtools 打开该文件,使用 coverage 面板启用 v8 coverage 功能,可以看出:
- 当统计口径为
per function时,可见sub函数没被覆盖到,但if else内第 10 行语句都被覆盖到了,与预期有些出入(预期'never execute'应该不被覆盖)。
- 当统计口径为
per block时,第九行被标记为全部被覆盖到,但实际上3>1的判断是并没有被执行的,此处与预期也有些出入(我猜测是 draw reporter 的逻辑比较粗糙)
TLDR: c8 调用了 node 内置 v8 coverage, 最后依据产物生成覆盖率文件。
当执行 c8 node index.js 时,其执行流程如下:
- 标记
NODE_V8_COV ERAGE来告知 node 将覆盖率中间产物放到何处。 - 通过
foreground开启另一个端口执行node index.js; - node 接收到
NODE_V8_COVERAGE变量; - 调用 profiler 来唤起 V8ProfilerConnection, 关于 V8 暴露出的 Profiler 接口,可以参考 Chrome-devtool/Profile
- 随后,运行过程中进入 V8 内部逻辑,以
precise/block模式为例,V8 会对诸如a ? b : c等可能存在执行不到的代码进行一些转化,例如转化为if (cond) {} else {}的模式,再增加相应的块级计数器来计数。除此之外,V8 还提供了 best-effort(性能优先),更多原理介绍可参考此篇博客. - 代码运行结束后,c8 开始以
NODE_V8_COVERAGE下的产物为基础进行覆盖率生成,除此之外,还有 sourcemap 等内容的处理,此处不再赘述。
虽然 c8 借助 Native Coverage 解决了性能问题,但相比与 NYC 而言,c8 依然存在很多不足,例如产物格式、用户生态等等。